
Seit Jahrhunderten träumen wir Menschen von Maschinen, die die Welt so verstehen wie wir; die uns zur Arbeit fahren, das Geschirr spülen oder uns sogar, wie der Star Wars R2D2 Roboter, auf einem Spaziergang begleiten. Damit so etwas je klappen kann, müssen Maschinen jedoch zunächst einmal lernen, Objekte in ihrer Umgebung zu erkennen. Konkret: Sie müssen die Tasse auf dem Tisch oder den Fußgänger an der Kreuzung als das erkennen können, was sie sind. Für uns Menschen ist das eine Selbstverständlichkeit, für Maschinen aber immer noch ganz schön schwer. Dass uns diese Fähigkeit an uns selbst gar nicht auffällt, hat vielleicht auch damit zu tun, dass menschliche Gehirne enorme Ressourcen zur Verarbeitung unseres visuellen Inputs einsetzen.
Bei der Entwicklung robuster maschineller Bilderkennungssysteme stellt sich eine wegweisende Frage: Auf welchem Weg können wir uns erfolgversprechend der menschlichen Fähigkeit, Objekte zu erkennen, annähern? Sollten wir versuchen, all unser biologisches Wissen über Hirnfunktion in die Maschinen zu packen? Oder sollten wir lieber einfach mal beiseitelassen, was wir über perzeptive Vorgänge beim Menschen wissen, und stattdessen die maschinellen Modelle umfassender, die Parameter zahlreicher und die Datensätze fürs Training größer machen, um Fortschritte zu erzielen?
Mit immer besseren Modellen bringen Forschende aus aller Welt das maschinelle Lernen stetig voran. Ihr Erfolg lässt sich sehen, zumindest, solange es sich um Bilder von Standardmotiven handelt, die bei Sonnenschein aufgenommen wurden. Denn selbst leistungsfähige Modelle mit ihren Abermillionen Parametern ticken in punkto Wahrnehmung oft ganz anders als der Mensch. Die Bedingungen brauchen nur ein wenig suboptimal zu sein, wie etwa bei verzerrten oder verrauschten Bildern, schon haben viele von ihnen Schwierigkeiten (Abb. 1).
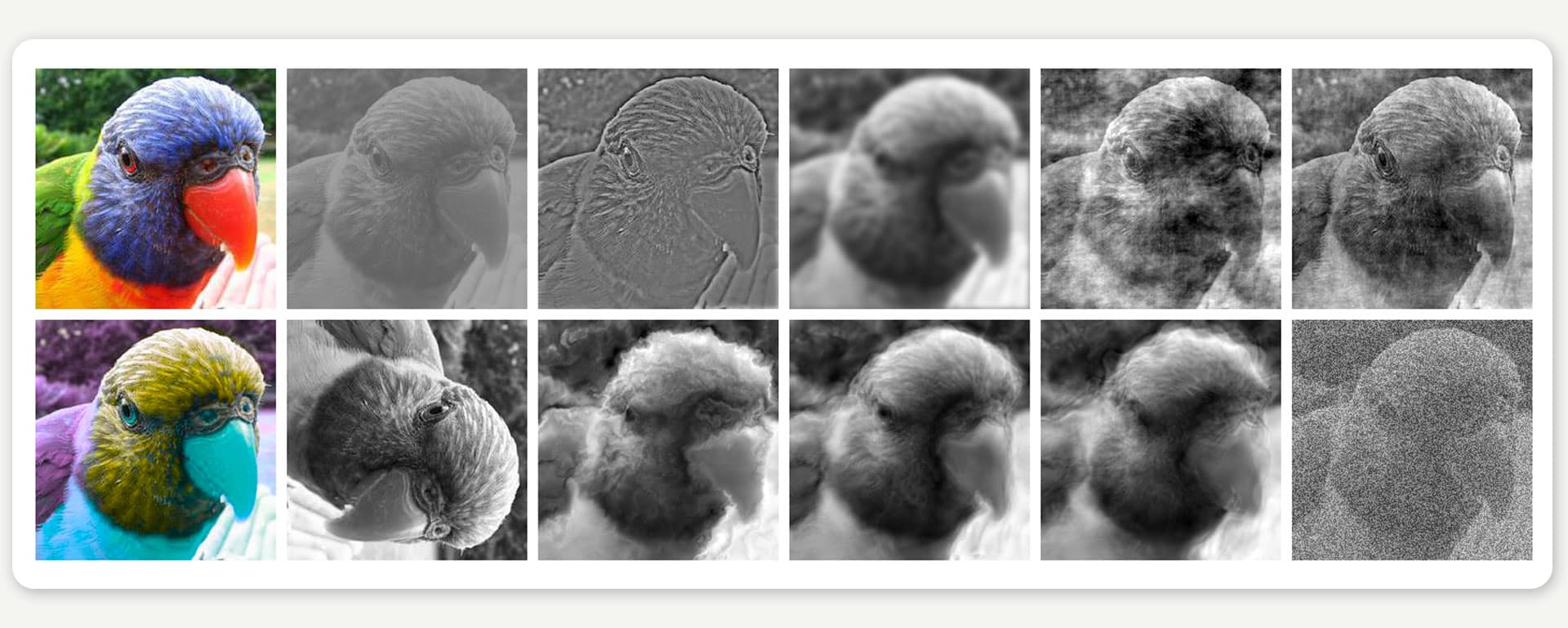
ABBILDUNG 1: Mit dem Erkennen von Bildern tun sich maschinelle Lernsysteme oft schwer, wenn es sich um Störungen oder Verzerrungen handelt, die sie so zuvor nicht gesehen hatten. Bildquelle: Geirhos et al., NeurIPS 2018.
Solche Bilder liegen jenseits der Variationsbreite der Bilder, mit denen maschinelle Lernsysteme klassischerweise trainiert werden („out of distribution“). Demgegenüber ist das Erkennen selbst schwer verzerrter Bilder für Menschen ein Kinderspiel. In einem gemeinsamen Projekt der Gruppen von Felix Wichmann, Matthias Bethge und Wieland Brendel unter Federführung von Robert Geirhos haben wir uns diesen Unterschied näher angeschaut. Dazu legten wir menschlichen Beobachtern einen riesigen Satz an verrauschten Bildern vor, die sie klassifizieren sollten (Vogel? Fahrrad? Boot? …). Diesen Datensatz haben wir zusammen mit den Antworten unserer Probanden als Open-Source-Python-Toolkit unter dem Namen „model-vs-human“ öffentlich zugänglich gemacht.
Unerwartet aber wahr: Die größten Datensätze bringen den größten Erfolg
Mit diesem Datensatz testeten wir maschinelle Lernsysteme der allerneuesten Generation, darunter auch solche, die sich durch radikale Unterschiede zu Standardmodellen auszeichnen. Manche stechen zum Beispiel dadurch hervor, dass sie mit Bildern und Texten in Kombination trainiert werden. Andere beinhalten sogenannte „Transformer“-Module, mit denen sie die globalen Merkmale von Bildern leichter erkennen können. Wie zu erwarten, machten die Standardmodelle bei verzerrten Bildern viel mehr Fehler als die menschlichen Probanden, und darüber hinaus machten sie auch andere Fehler als Menschen: Bei manchen Bildern, die von allen Probanden richtig erkannt wurden, versagten sie durch die Bank. Dafür machten Menschen einige Fehler, die keiner Maschine unterlaufen waren. Einige der neuesten Modelle zeigten jedoch, dass die algorithmische Bilderkennungsfähigkeit zur menschlichen immer mehr aufschließt. Überraschend war für uns, dass nicht die Art des Modells, sondern insbesondere der Umfang der Trainingsdaten für den Erfolg entscheidend war. Auch ein Standardmodell ist in der Lage, verzerrte Bilder, die es vorher nie gesehen hat, so gut oder sogar besser als ein Mensch zu erkennen – wenn es zuvor mit extrem vielen Daten gefüttert wurde. Vielleicht noch verwunderlicher: Modelle, die auf gigantisch großen Datensätzen trainiert wurden, machten auf einmal deutlich menschenähnlichere Fehler!
Dabei gingen aber ausgerechnet die Maschinen mit den menschenähnlichsten Fähigkeiten ganz anders vor, als das Menschen naturgegeben tun. Größere Datensätze fürs Training scheinen deutlich effektiver zu sein als jedes Bemühen um ein „biologisch inspiriertes“ Lernen, wie etwa das sogenannte self-supervised learning. Dieser Lernform liegt die Annahme zugrunde, dass Kleinkinder, während sie versuchen, Objekte in ihrer Umgebung zu erkennen, nicht millionenfach gesagt bekommen müssen, wie die Objekte heißen. Ebenso wies keines der untersuchten Modelle, die beim Einordnen von Bildern an menschliche Leistungen herankamen, jene biologisch inspirierten Merkmale auf, die oftmals als unabdingbar galten (wie z.B. den Einsatz rekurrenter Verbindungen).
Von der Biologie abkupfern – ein verführerischer Irrweg?
Wir vermuten, dass sich daraus etwas sehr Grundlegendes lernen lässt. Im maschinellen Lernen sind wir momentan darauf aus, Wunderleistungen der Natur (wozu auch die Fähigkeit der robusten Objekterkennung unter schwierigen Bedingungen gehört) mit Mitteln der Technik nachzuahmen. Ein bisschen erinnert das an die lange Jagd unserer Vorfahren nach dem Traum des Fliegens: Über Jahrhunderte versuchten Generationen von Erfindern, Fluggeräte zu bauen, die dem Vorbild der Natur nachempfunden waren. Von den aus Wachs und Federn gefertigten Flügeln des Icarus und Dädalus bis zu Leonardo Da Vincis detaillierten Skizzen seiner Flugmaschinen zeugen viele Beispiele von der Versuchung früher Flugingenieure, den Vogelflug möglichst naturgetreu zu imitieren. Dazu gehörte etwa die Struktur und Form der Flügel sowie eine Vorrichtung, um mit den Flügeln vogelgleich zu flattern (wofür da Vinci in einer seiner Skizzen beidseits T-förmige Streben vorsah, die zur Mitte hin gezogen werden sollten).

ABBILDUNG 2: Leonardo Da Vinci orientierte sich in seinen Zeichnungen von Flugmaschinen am Vogelflug. Illustration: Franz Stämmele/Universität Tübingen.
So genial die damaligen Erfinder mit ihren Ideen auch waren, verfielen sie jedoch oft dem Irrweg, bis ins kleinste Detail von der Natur abzukupfern. Heute haben Flugzeuge weder Federn noch flatternde Flügel. Die größten Erfolge kamen erst, als man aufhörte, die biologischen Vorbilder haarklein nachzuahmen, und stattdessen begann, die Gesetze der Aerodynamik, Strömungslehre und dergleichen zu verstehen: Prinzipien, die dem Fliegen (egal welcher Art) zugrunde liegen.
Könnte dies heute bei der Weiterentwicklung des maschinellen Lernens eine wichtige Lehre für uns sein? Vielleicht sollten wir uns vom zwanghaften Nachahmen der Natur („gefiederte Flugzeuge“) lösen und uns mehr um ein Verständnis der Grundprinzipien und algorithmischen Muster kümmern, die sich bei der Lösung komplexer Aufgaben bewähren. Unsere Ergebnisse zeigen, dass die erfolgreichsten Modelle sich gerade nicht nennenswert an biologischen Vorbildern orientieren. Im Gegenteil: Ein primitives Verzehnfachen oder Verhundertfachen der Datensatzgröße ist viel effektiver als das Bemühen um biologisch naturgetreue Lernstrategien. Angelehnt an Rich Sutton, den kanadischen Pionier des maschinellen Lernens, könnte man sagen: „Einzubauen wie wir denken, dass wir denken, funktioniert auf lange Sicht hier nicht.“
Orignialpublikation:
Geirhos, R., Narayanappa, K., Mitzkus, B., Thieringer, T., Bethge, M., Wichmann, F. A., & Brendel, W. (2021). Partial success in closing the gap between human and machine vision. Advances in Neural Information Processing Systems 34.
Paper: https://openreview.net/forum?id=QkljT4mrfs
Code: https://github.com/bethgelab/model-vs-human
Text: Robert Geirhos
Übersetzung ins Deutsche: Conrad Heckmann
Titelillustration: Franz Stämmele/Universität Tübingen

Maschinelles Lernen entschlüsselt Beben im Universum

Kommentare