
For centuries, humans have dreamt of machines that can understand the world like us – machines that can drive us to work, do the dishes, and perhaps even accompany us on a walk like Star Wars’ R2-D2 robot. For all of those tasks, being able to recognize objects in the world around us is a key prerequisite – whether it is a mug on the table or a pedestrian on a crosswalk. While this is easy for us, being able to robustly recognize objects is still very challenging for machines – perhaps because our brains are devoting massive resources to processing visual input, making the difficult appear trivial. When it comes to designing robust machine vision systems, we are facing a key question: which direction is going to narrow the gap towards human-level perceptual abilities? Should we try to incorporate as much knowledge we have about biological brains into machines? Or, on the other hand, should we rather ignore what we know about human perception and simply strive for larger models with more parameters in the hope that they will learn how to solve the problem through training on ever-larger datasets?
Machine learning researchers around the world have continually developed better and better models – at least when it comes to recognizing objects in standard images photographed on a sunny day. However, even advanced models with dozens of millions of parameters strikingly deviate from human perception, and many of them struggle with less-than-perfect conditions such as recognizing objects on distorted images (Fig. 1):
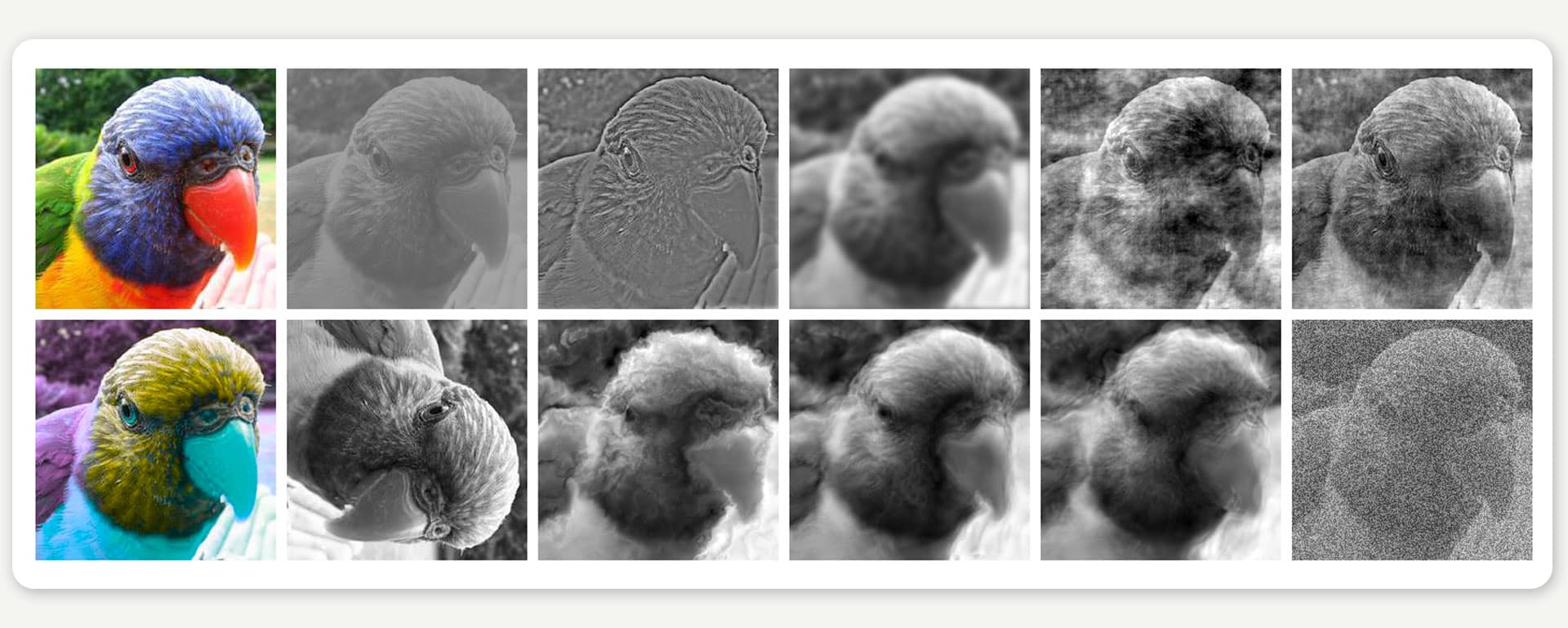
FIGURE 1: Machine learning models often struggle to recognize images with unexpected distortions. Image source: Geirhos et al., NeurIPS 2018.
Those images are called “out-of-distribution” since they systematically deviate from the standard images that machine learning models are trained on. Humans, on the other hand, have little trouble recognizing even severely distorted images. In a collaborative effort by the Wichmann, Bethge and Brendel labs led by Robert Geirhos, we decided to study this deviation in more detail. To this end, we collected a massive set of human classification data, asking human observers to identify the object in an image (Bird? Bicycle? Boat? …). We have made this dataset, along with human decisions, publicly available as an open-sourced Python toolkit and benchmark called “model-vs-human”.
The unreasonable effectiveness of large datasets
Using this data set, we then tested the very latest generation of machine learning models, including many that are off the beaten track in certain ways. For example, some of them are unusual in the sense that they are jointly trained on images and text, while other models incorporate recently developed “transformer” building blocks that make it easier for them to focus on global properties of images. As expected, standard “vanilla” models made much more errors on distorted images than humans, and they also made errors on very different images – that is, they failed to recognize some images on which all human observers were correct, but they also correctly recognized some images on which all humans failed. However, a number of recent models made substantial progress towards closing the gap between algorithms and humans. Contrary to our expectations, the most crucial factor was not the type of model, but rather the amount of training data. Training standard models on extremely large datasets was sufficient to reach or surpass human-level performance on distorted images they had not seen during training. Perhaps even more surprisingly, to a certain degree those models started to make errors on the same images as humans!
This similarity to human object recognition decisions is particularly significant given that none of those models exhibiting more human-like decisions is particularly biologically faithful – and in fact, just using a larger dataset for model training appears much more effective than a biologically-inspired form of learning (self-supervised learning) which is based on the notion that humans don’t require millions of correctly labeled examples when learning to recognize objects. Moreover, none of the models with emergent human-like classification patterns in our benchmark incorporate biologically-inspired implementations which have often been thought to be crucial (such as, e.g., the use of recurrent connections).
The biological realism trap
In our interpretation, there is something fundamental to be learned from this. In present–day machine learning, we are seeking to emulate brilliant feats of nature (like the ability to robustly recognize objects under challenging conditions) with technical devices. In some ways, this is reminiscent of mankind’s age-old struggle to fly: For centuries, inventors have attempted to build flying technical devices inspired by natural flight. From Icarus and Daedalus’ wings made of feathers and wax, to the detailed sketch of a flying machine by Leonardo da Vinci (Fig. 2), it certainly appears tempting to copy birds as closely as possible, including the structure and shape of their wings, and their ability to flap those wings (in da Vinci’s sketch, flapping would be achieved by pulling the T-shaped support bars – one on each side – towards the middle).

Figure 2: Leonardo Da Vinci modeled his sketches of flying machines on the flight of birds. Illustration: Franz Stämmele/University of Tübingen.
Unfortunately, as ingenious as those attempts and inventors were, they all fell into what might be called the “biological realism trap”. Today’s airplanes don’t have feathers and flapping wings – ultimately, it has proven much more successful to understand the central principles behind bird flight, and flight in general – aerodynamic forces, fluid dynamics, and the like – instead of copying the biological role model as closely as possible.
This may be an important lesson for machine learning today. Should we, perhaps, worry more about understanding the core principles and algorithmic patterns behind complex tasks and less about building biologically faithful implementations (“airplanes with feathers”)? Our results indicate that none of the most successful models has a particularly biologically realistic implementation, and in fact, simply training models on large-scale datasets appears much more effective than for instance biologically-motivated learning strategies. In the words of Canadian machine learner Rich Sutton, “building in how we think we think does not work in the long run”.
Original publication:
Geirhos, R., Narayanappa, K., Mitzkus, B., Thieringer, T., Bethge, M., Wichmann, F. A., & Brendel, W. (2021). Partial success in closing the gap between human and machine vision. Advances in Neural Information Processing Systems 34.
Paper: https://openreview.net/forum?id=QkljT4mrfs
Code: https://github.com/bethgelab/model-vs-human
Cover illustration: Franz Stämmele

Machine Learning Decodes Tremors of the Universe

Comments