
Despite much progress, the black-box nature of the decisions of a deep learning algorithm is still a major obstacle for their widespread use in safety-critical application domains, such as healthcare. One reason for this shortcoming is that we tell the model what it should predict only through human-labeled training data and let it automatically infer how to make those predictions. For complex models trained on large datasets, it is thus often not clear, why they make certain predictions. In particular, classifiers can also pick up spurious signals in the data, which prevent them from learning the actual desired concepts.
For example, if we train a model to distinguish several animal breeds such as dogs, cats and cows from each other, the model should use similar features as humans, e.g. a cat image should be classified as a cat, because there are typical features like a cat’s ears or fur patterns. However, if our dataset contains certain biases, it can lead to misclassifications: for example, if most dog images are taken in a forest, but most cat images are taken inside, it is possible that the automatic training procedure classifies an image showing a dog inside as a cat. This is due to the fact that the automatically trained model has learned that the background is a stronger or easier predictor for the animal breed than the actual animal.
Existing methods for explaining image classification models are often based on heatmaps or saliency maps, i.e. they highlight the part of the image that had the most influence on the prediction. However, these maps do not answer why this part of the image actually led to the prediction, which then again requires interpretation by domain experts. To this end, we have developed algorithms for creating Visual Counterfactual Explanations (VCEs). VCEs are image specific explanations of a classifier that are close to human justification of decisions: “I would recognize this image of a horse as a zebra, if it had black and white stripes.” More formally, these methods take a trained classifier and solve the following problem: “Given a target class c, such as zebra in the previous example, how would the image have to look like to be labeled as zebra by our model, while remaining similar to the original horse image?”.
Diffusion Visual Counterfactual Explanations (DVCEs)
In our recently published paper, we have proposed a new algorithm to use popular generative models, called diffusion models, to generate such VCEs (DVCEs). Generative models are models trained to generate new images that are similar but not identical to the original images seen during training.

Figure 1. Our method DVCE creates visual counterfactual explanations (VCEs) that explain any given classifier by changing an image of one class into a similar target class by changing class relevant features, while preserving the overall image structure. On the left, we change the prediction of a chimpanzee image into two different breeds of apes. Similarly, on the right, we change the prediction of one breed of a retriever into two different ones.
Minimal
For us, it is important that our DVCEs fulfill several criteria.
First, the change to the original image should be minimal. Generative models are very good at generating images for a target class like zebra, however, for our problem of explaining classifiers, it is not useful, if the resulting image does not resemble our starting image and instead is a completely unrelated image of a zebra on a different background. To ensure that the classifier focuses on the requested object, our explanation method only manipulates the most important parts of the image: in this case transforming the fur of the horse into a black and white zebra pattern, while keeping the background the same.

Realism
Also, the images should look realistic. For example, it might be very easy to make a cat vs. dog classifier predict cat, by pasting in several “cat’s ears” all over the image, however this would not be realistic. Instead, a more realistic DVCE would maybe change the ears on a given dog image into cat’s ears and introduce fur patterns that are prototypical for a cat.
Our DVCEs rely on diffusion models to create more realistic images. Diffusion models have learnt “what real images look like” by analyzing millions of different images.
Now that we have an idea of how DVCEs work, what can we practically gain with them?
Debugging Classifiers
One way to apply DVCEs is via discovering the bias learned by the classifier. For example, in Figure 3 we show that an image classifier that was trained on many images containing flowers for the class “bee” (examples can be seen on the right) generates flowers for a DVCE into the class “bee” but no actual bees. This shows that the classifier has learned to predict this class even when no bees and only flowers are present.

Figure 3. DVCE (middle) of the original image (left) for an ImageNet classifier having the spurious feature “flower” for the target class “bee” (that means images just containing flowers have already high chance of being classified as bee). On the right, a sample from the ImageNet training set is shown.
DVCEs for medical classifiers
Moreover, such explanations can be readily used for the medical applications, such as classification of diabetic retinopathy with fundus images. For this task we have already generated VCEs for any image classifier in a recent paper. However, to increase realism, we are working on applying DVCEs for them as can be seen in Figure 4. Here, for a fundus image of an eye with a diabetic retinopathy (DR), that is also predicted to have DR by a classifier, we generate a DVCE into the target class “healthy” that removes the main markers of disease (e.g., red hemorrhages and yellow hard exudates are removed, and arteries are continued) naturally. Such DVCEs can help doctors to make decisions when using deep learning image classifiers, as this way doctors can see better why a model makes a particular decision.
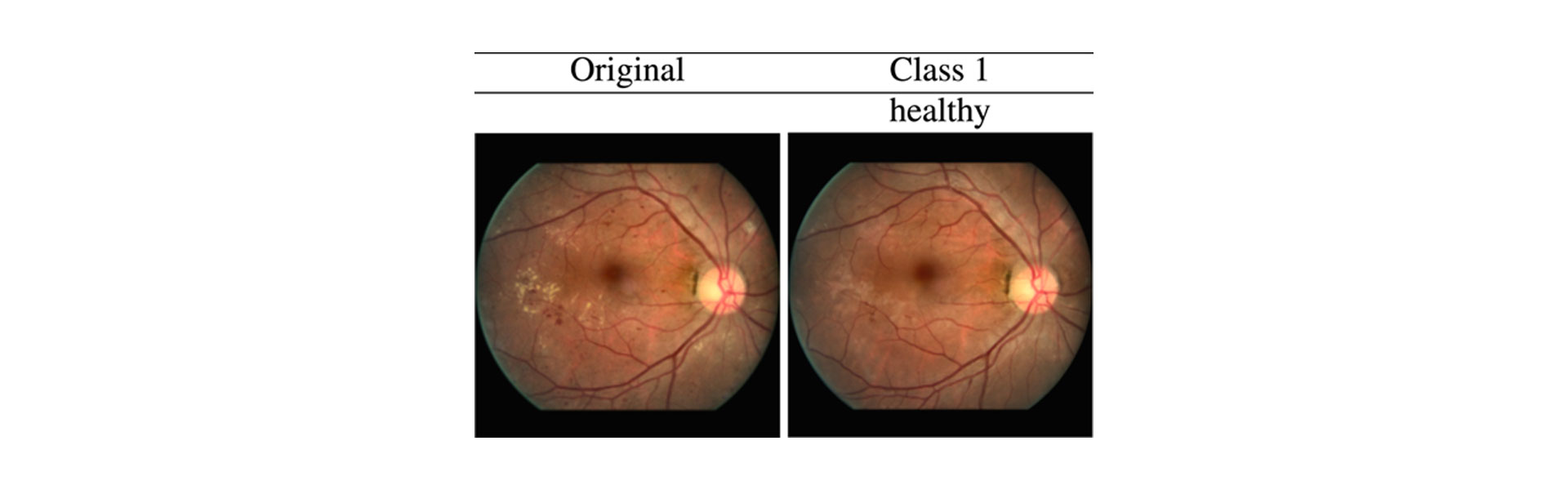
Figure 4. DVCEs for a classifier change the image naturally from the sick class (DR) to the healthy one and remove main markers of disease.
A Glimpse inside the Black-Box
The demand for transparency is not only directed at decisions affecting humans but is a pressing matter in all applications of machine learning. This is because humans would like to understand but also control if the learning algorithm has captured the concepts of the underlying classes or if it just predicts well using spurious features, which can stem from the artefacts in the dataset. Although there is still a lot we don’t know and many areas remain in the dark, our DVCEs help to understand parts of the decision-making process by making small, but realistic changes in images using a diffusion process. This way we can track the model’s decisions more precisely and get one step closer towards transparency by opening up the “black-box” of models.
Original publication:
Maximilian Augustin, Valentyn Boreiko, Francesco Croce, Matthias Hein: Diffusion Visual Counterfactual Explanations. Advances in Neural Information Processing Systems (NeurIPS), 2022
Paper: https://arxiv.org/abs/2210.11841
Cover illustration: Franz-Georg Stämmele
Machine Learning Improves
Super-resolution Microscopy

Painless Uncertainty for Deep Learning

Comments