
In the Allegory of the Cave by Plato, a group of people are imprisoned in a cave from childhood on. They perceive the world only as shadows of objects projected onto a blank wall. One day, a single prisoner is freed to leave the cave to experience the world as we do – with 3D objects, colors, shadow and light. Amazed by the fundamentally different nature of reality, imagine he would go back into the cave and try to describe the world to the other prisoners. This would be a difficult endeavour when all the people inside the cave ever saw were shadows on a blank wall.
Similarly, computer vision pursues teaching machines to “see” the world as we do. Typically, this is done by showing the machine large collections of images and training them to make predictions based on these images. But images are only a projection of the real world, similar to the shadows that the prisoners in Plato’s cave observe. This makes inferring 3D properties a notoriously difficult task. Nonetheless, for many downstream applications modelling the 3D nature of our world is crucial. For example, when training autonomous agents like cars, simulation is key to creating scenarios for which data is difficult to capture in the real world. Collecting real-world data might be undesirable due to safety aspects, e.g. simulating a situation where a kid runs unexpectedly onto the street, or difficult to observe because it is an unlikely, but not impossible, scenario, like a zebra running across the street.
The data problem
If images are not ideal to infer 3D properties, why don’t we just use large collections of 3D models and 3D environments to train our algorithms?
The answer is both simple and sobering – because this data is not readily available. Every smartphone is shipped with a camera which makes collecting images straightforward. But reconstructing accurate 3D models typically requires careful scanning of the object by recording hundreds of images with known camera poses. Then, these images have to be stitched together, ensuring that both the geometry and texture of the object are fused seamlessly which is a difficult and tedious process.
And while images might not be perfect as training data, they can still convey important visual cues. Consider looking at a photo of a car in some magazine. You can easily imagine how it looks from the back, or how it would look in another colour. This is possible because you have seen thousands of other cars before and you have learned an abstract concept of a car that includes 3D information like a rough shape of the car and rules of symmetry.
We follow the same approach and train our algorithm with thousands of images of different cars from which it can learn the general properties of a car like shape or appearance.
Modelling the image formation process
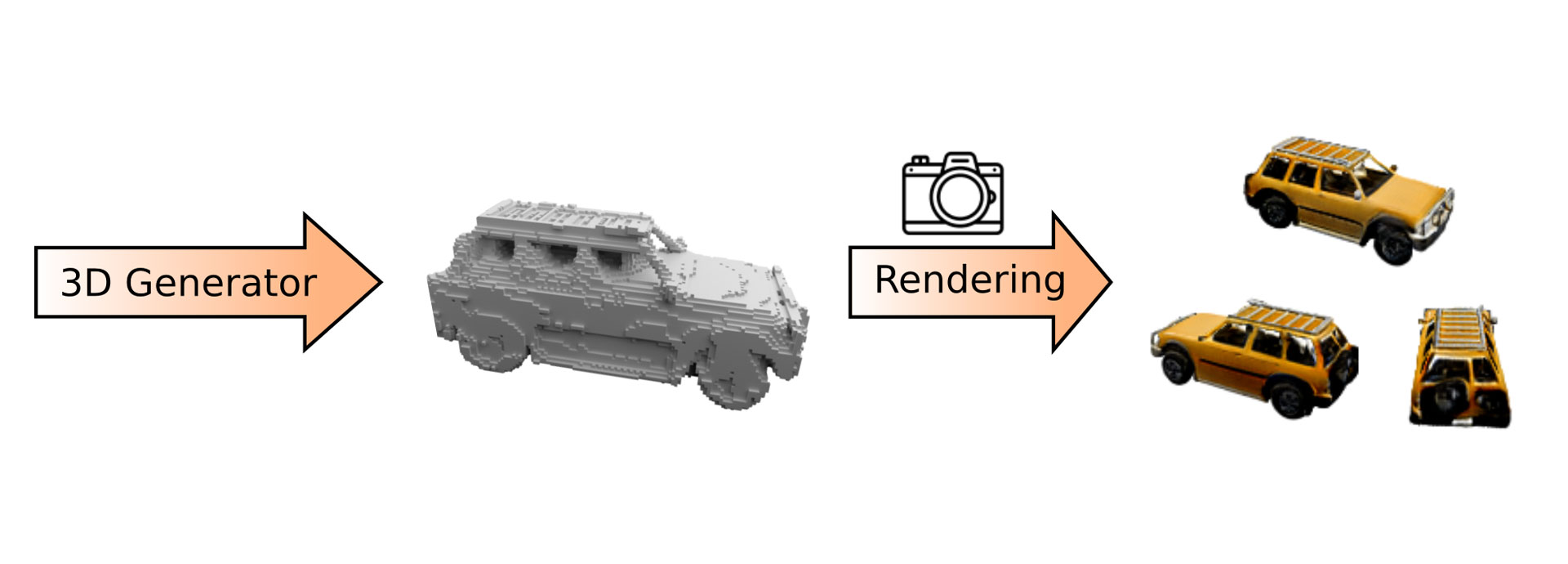
Figure 1: Our algorithm first generates an object with a 3D generator. The 3D object is then rendered from an arbitrary viewpoint to form an image.
While our algorithm should learn to generate 3D objects, we can only use images to supervise the training process. Hence, we project the generated 3D object onto a 2D image which we then compare to a real image from the training data. This projection step is called “rendering” and can be added to our algorithm by including a virtual camera model. Fig. 1 shows a schematic overview of our algorithm. Our algorithm first generates a 3D object which is subsequently rendered to form an image. We can position the virtual camera at any point to render an image. This way we can use our algorithm to generate videos like the one below.

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Computational cost in 3D
Another challenge when working with 3D data is the computational cost of the algorithms. Images are digitally represented as arrays of pixels (picture elements). Consider an image with resolution 256^2 pixels. Doubling the resolution results in 4 times as many pixels, namely, 512^2 pixels, i.e. the number of pixels grows quadratically with the resolution. The 3D equivalent to pixels is called voxels (volume elements). When doubling the resolution of a voxel grid, the number of voxels grows cubically, i.e. by a factor of 8. Hence, representing 3D objects on voxel grids can quickly become extremely memory intensive.
The good news is that most of the space in 3D is actually empty, e.g. when modelling a car on a street there will be a lot of free space, as there are only a few cars and other objects but most of the space will be filled with air. Further, it is typically sufficient to only model the surface of the objects. Therefore, we do not need to store a voxel for every point in 3D. By designing our algorithm to ignore empty voxels we ensure that the computational cost remains feasible. Fig. 3 shows the generated voxel grids together with the rendered images.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
What’s next?
Our approach demonstrates that machines can indeed learn 3D properties of objects only from large collections of 2D images. In the long run, it will be interesting to generate more complex scenes and environments with which autonomous agents can interact. Another fascinating research direction is text-driven image synthesis. Here, the user describes in words what the algorithm should generate and the model will create an image based on that description. Very recently, the same principle was applied to generate 3D objects based on text prompts opening up a plethora of creative applications that combine text and vision.
Original publication:
K. Schwarz, A. Sauer, M. Niemeyer, Y. Liao and A. Geiger. VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids. Advances in Neural Information Processing Systems (NeurIPS), 2022
Paper: https://www.cvlibs.net/publications/Schwarz2022NEURIPS.pdf
Project site: https://katjaschwarz.github.io/voxgraf/
Cover illustration: Franz-Georg Stämmele

Using Machine Learning for 3D Soil Mapping

Do machines see like humans? They are getting closer

Comments