
Stellt euch vor, ihr seid Historikerin oder Historiker und möchtet rückblickend verstehen, welchen Einfluss die Covid-19-Pandemie auf die wissenschaftliche Literatur hatte. Nach einer kurzen Suche mit dem Stichwort „Covid-19“ werdet ihr von der Informationsflut überwältigt sein, denn jedes Jahr werden in der Biomedizin und den Lebenswissenschaften mehr als eine Million wissenschaftliche Artikel veröffentlicht. Mit Suchmaschinen wie Google Scholar kann man zwar bestimmte Artikel finden, aber es ist nicht möglich, einen Überblick über alle existierenden Artikel zu bekommen. Es wäre daher schwierig zu erkennen, wie sich die Publikationen über Covid-19 im Laufe der Zeit entwickelt haben oder welche Verbindungen zu anderen Forschungsfeldern bestehen, ohne sich monatelang mit der Literatur befassen zu müssen.
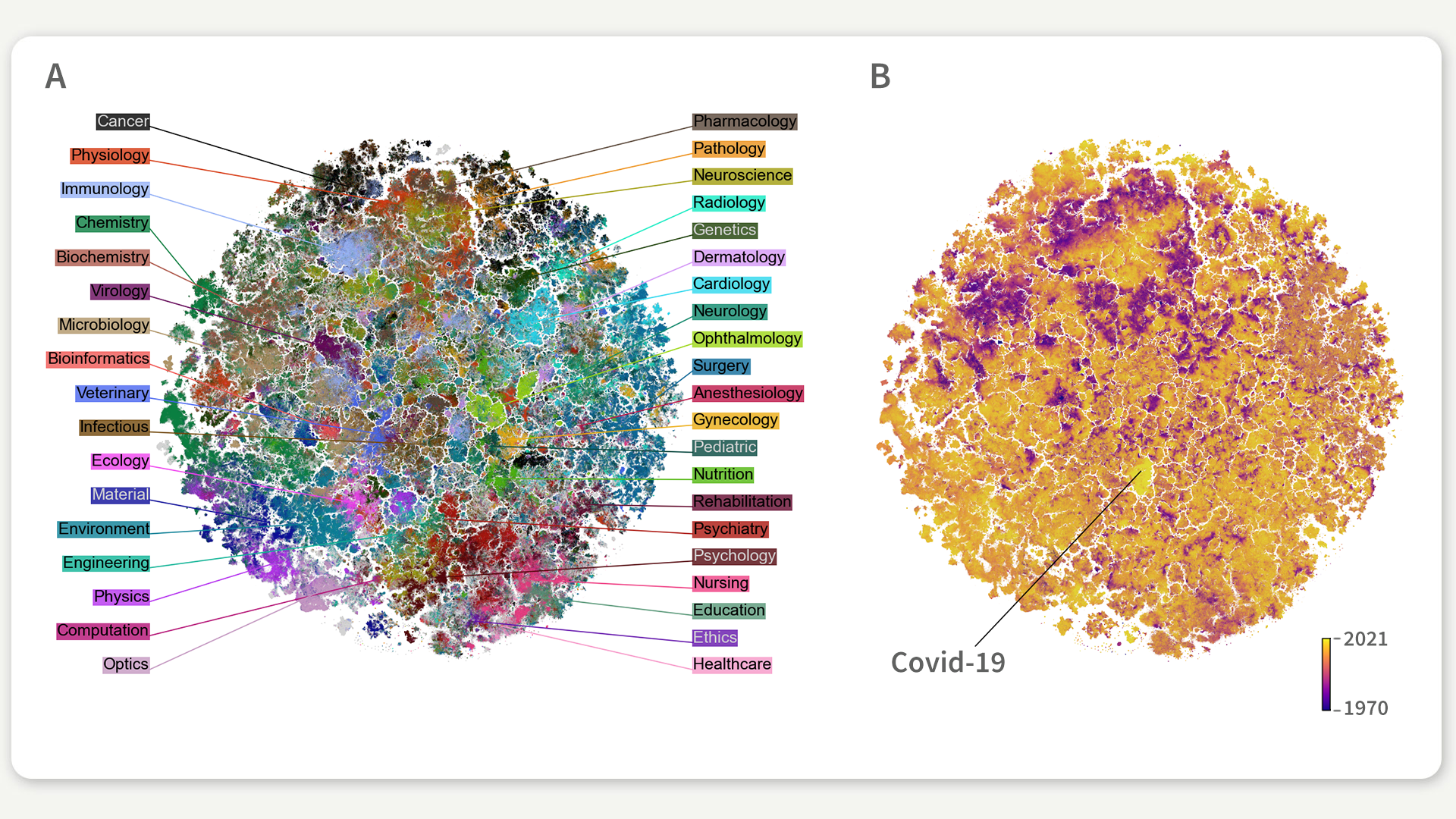
Abbildung 1: Karte der biomedizinischen Forschungslandschaft, eingefärbt nach (a) Disziplin, (b) Publikationsjahr. Jeder Punkt auf der Karte steht für einen der 20 Millionen wissenschaftlichen Artikel, die in der Datenbank PubMed erfasst sind.
Um den zukünftigen Historikerinnen und Historikern und anderen Forschenden in ähnlichen Situationen die Arbeit zu erleichtern, haben wir eine Karte der gesamten biomedizinischen Literatur erstellt, die es möglich macht, durch 20 Millionen Artikel gleichzeitig zu navigieren und Verbindungen zwischen ihnen zu erkennen. Die Karte basiert auf allen wissenschaftlichen Artikeln aus PubMed, einer der bekanntesten Datenbanken für Biomedizin und Biowissenschaften – die darüber hinaus auch viele andere Disziplinen abdeckt, von Physik und Ingenieurwissenschaften bis hin zu Biologie und Kardiologie. Ihr könnt euch sicher vorstellen, wie komplex es ist, so viele Artikel aus so unterschiedlichen Fachgebieten auf einer Karte zu organisieren. Deshalb nutzen wir dafür Methoden des maschinellen Lernens.
Die Karte ist interaktiv und bietet nicht nur einen Überblick über die biomedizinische Literatur, sondern ermöglicht es auch, bis ins kleinste Detail jeder einzelnen Disziplin zu blicken und nach Titeln, Zeitschriftennamen, Autorinnen und Autoren oder Stichwörtern zu suchen. So könnten eine Historikerin oder ein Historiker Covid-19-Artikel auf der Karte finden und sehen, mit welchen anderen Disziplinen diese Artikel eine Verbindung haben. Tatsächlich würden sie feststellen, dass sich fast alle Covid-19-Artikel in einer Insel in der Mitte der Karte befinden (hellgelbe Insel, Abbildung 1b), umgeben von Artikeln über andere Epidemien und Atemwegserkrankungen. Innerhalb dieser Insel befinden sich, unterteilt in verschiedene Bereiche, Covid-19-Artikel mit unterschiedlichen Schwerpunkten, z. B. Auswirkungen auf die psychische Gesundheit, Impfstoffe, Symptome oder Behandlungen. Die Karte könnte es Historikerinnen und Historikern ermöglichen, durch die verschiedenen Themenbereiche der Covid-19-Literatur zu navigieren und zu sehen, wie sie untereinander verbunden sind. Letztendlich würden sie feststellen, dass die Covid-19-Literatur auf besondere Weise vom Rest der Karte abgetrennt ist, was bei anderen Epidemien wie HIV oder Ebola nicht der Fall ist. Die Karte zeigt also, wie die Covid-19-Pandemie nach nur zwei Jahren einen beispiellosen Einfluss auf die wissenschaftliche Literatur hatte.
Der Mechanismus der Karte
Und wie wird die Karte erzeugt? Wir nutzen Methoden des maschinellen Lernens, um die Abstracts der 20 Millionen PubMed-Artikel nach Inhalten zu sortieren und in der Karte zu verorten. Dafür verwenden wir ein großes Sprachmodell (Large Language Model, LLM), das spezifisch mit biomedizinischen Texten (PubMedBERT) trainiert wurde. Ähnlich wie der Chatbot ChatGPT ist dieses große Sprachmodell ein fortgeschrittenes Machine-Learning-System, das aus großen Textmengen lernt, Texte zu „verstehen“.
Mit Hilfe dieses Sprachmodells haben wir den Inhalt jedes Abstracts in Zahlen übersetzt. Dann haben wir ein weiteres maschinelles Lernverfahren (t-SNE) verwendet, das automatisch jedes Abstract als einen Punkt auf einer 2D-Karte platziert, so dass jeder Artikel von Artikeln mit ähnlichem Inhalt umgeben ist. Die Papers werden dann auf der Karte entsprechend ihrem Fachgebiet oder anderen Merkmalen, wie dem Erscheinungsjahr, eingefärbt.
Große Sprachmodelle (Large Language Models, LLMs) sind zu beeindruckenden Leistungen fähig. Sie können menschenähnliche Texte erzeugen, Texte kategorisieren oder in eine andere Sprache übersetzen. Weit verbreitete Tools, wie z.B. ChatGPT, haben das Potenzial, unsere Produktivität zu steigern und uns das autodidaktische Lernen zu erleichtern. Gleichzeitig werfen sie Fragen nach der Urheberschaft und der Glaubwürdigkeit der bereitgestellten Informationen auf. Aber wie lernen LLMs? Die Modelle verstehen Text zwar nicht wie wir Menschen, aber sie sind richtig gut darin, Muster zu erkennen. Sie können statistische Beziehungen zwischen Wörtern und ihrem Kontext lernen und, darauf basierend, diese Beziehungen durch Zahlenreihen darstellen. Zum Beispiel könnten sie in einem Satz wie „Die Katze saß auf der Matte“ das Wort „Katze“ durch die Zahlen [0,8, -0,4, 0,2], das Wort „saß“ durch [0,1, 0,6, -0,3] usw. darstellen. Ähnliche Wörter in ähnlichem Kontext erhalten ähnliche Zahlenfolgen. So kann ein ganzer Satz durch eine Folge von Zahlen anstelle von einzelnen Wörtern dargestellt werden, ohne dass der Inhalt verloren geht. Das ist für die Anwendung maschineller Lernverfahren notwendig, da Computer nur mit Zahlen arbeiten können.
Über die Literaturrecherche hinaus
Da wir auch an maschinellem Lernen im Allgemeinen interessiert sind, haben wir die Karte verwendet, um zu analysieren, wie verschiedene medizinische Disziplinen Methoden des maschinellen Lernens (ML) bisher eingesetzt haben. Inzwischen werden in der Medizin immer mehr Methoden des maschinellen Lernens angewendet, etwa für die Diagnose oder personalisierte Behandlungen. Die Karte zeigt, dass einige Bereiche, wie z.B. die Radiologie, die neuen Tools schneller integriert haben als andere, wie z.B. die Gynäkologie, wo nach wie vor kaum ML-Methoden genutzt werden. Das ist nachvollziehbar, da die Radiologie in hohem Maße bildgebende Verfahren verwendet und Methoden des maschinellen Lernens, die mit Bildern arbeiten, in den letzten Jahren stark weiterentwickelt wurden.

Abbildung 2: Karte eingefärbt nach dem vorhergesagten Geschlecht des Erstautors der Arbeit (blau: männlich, orange: weiblich). Die Vergrößerung zeigt ein Beispiel für einen hohen Anteil weiblicher Autoren in einem männerdominierten Fachgebiet (weitere Details siehe Text).
Ein Problem, das in der Wissenschaft viele bewegt, ist das Ungleichgewicht zwischen den Geschlechtern bei der Autorschaft von Artikeln. In unserer Karte sind 42,4 % der Erstautoren und nur 29,1 % der Letztautoren Frauen – ein Hinweis auf den geringen Anteil von Frauen in Führungspositionen in der Wissenschaft. Autorinnen sind zudem häufiger in den eher sozialen Disziplinen der Biomedizin, wie etwa der Krankenpflege, der Pädagogik oder der Psychologie vertreten, während sie in den eher technischen Disziplinen wie Physik oder Informatik am wenigsten vorkommen. Im rein medizinischen Bereich ist die Chirurgie die Disziplin mit dem geringsten Frauenanteil (24,4 %). Mit unserer Karte können wir noch einen Schritt weiter gehen und geschlechtsspezifische Unterschiede innerhalb einzelner Fachbereiche untersuchen. So können wir z. B. innerhalb der Chirurgie eine Region mit einem überraschend hohen Frauenanteil (61,1 %) finden, es handelt sich dabei um Beiträge zur Veterinärchirurgie. Das entspricht der Tatsache, dass die Veterinärmedizin ein eher von Frauen dominiertes Gebiet ist (insgesamt 52,2 %).
Die Karte zeigt also deutlich, in welchen Bereichen Frauen nach wie vor unterrepräsentiert sind. Sie ist ein hervorragendes Instrument, um geschlechterspezifische Unterschiede in der biomedizinischen Forschungslandschaft zu untersuchen.
Hinweise auf betrügerische Forschung und Paper Mills
Nachdem wir die erste Version unserer Karte veröffentlicht hatten, kontaktierte uns ein Forscher, der sich für die Publikationen interessierte, die nach ihrer Veröffentlichung zurückgezogen wurden. Er fragte sich, ob diese Artikel mit sogenannten Paper Mills zusammenhängen könnten. Bei zurückgezogenen Publikationen handelt es sich um Artikel, die nach ihrer Veröffentlichung wegen Plagiaten, Fehlern, ethischen Verstößen oder der Fälschung von Daten und betrügerischer Forschung zurückgezogen werden. Viele dieser zurückgezogenen Arbeiten stammen von Paper Mills: gewinnorientierten Organisationen, die die Urheberschaft betrügerischer Forschungsarbeiten produzieren und verkaufen (1, 2). Wenn zum Beispiel ein Arzt, der in einem Krankenhaus arbeitet, eine bestimmte Anzahl an Forschungsarbeiten pro Jahr veröffentlichen muss, aber keine Zeit hat, selbst zu forschen, kann er bei diesen Paper Mills eine fertige Arbeit kaufen – die manchmal sogar schon von einer Zeitschrift angenommen wurde – und damit seine Verpflichtungen leichter erfüllen. Die Karte zeigt, dass sich die zurückgezogenen Arbeiten auf bestimmte Forschungsbereiche konzentrieren, z. B. im Bereich der Krebsmedizin – ein Forschungsbereich, der bekanntermaßen zu den Zielgebieten der Paper Mills gehört. Selbst viele der nicht zurückgezogenen Arbeiten in diesen Bereichen sind den zurückgezogenen auffallend ähnlich, was darauf hindeuten könnte, dass auch sie von Paper Mills stammen. Unsere Karte könnte daher verwendet werden, um Regionen mit einem ungewöhnlich hohen Anteil an zurückgezogenen Papers zu untersuchen und verdächtige Veröffentlichungen zu identifizieren, die eine genauere Überprüfung erfordern.
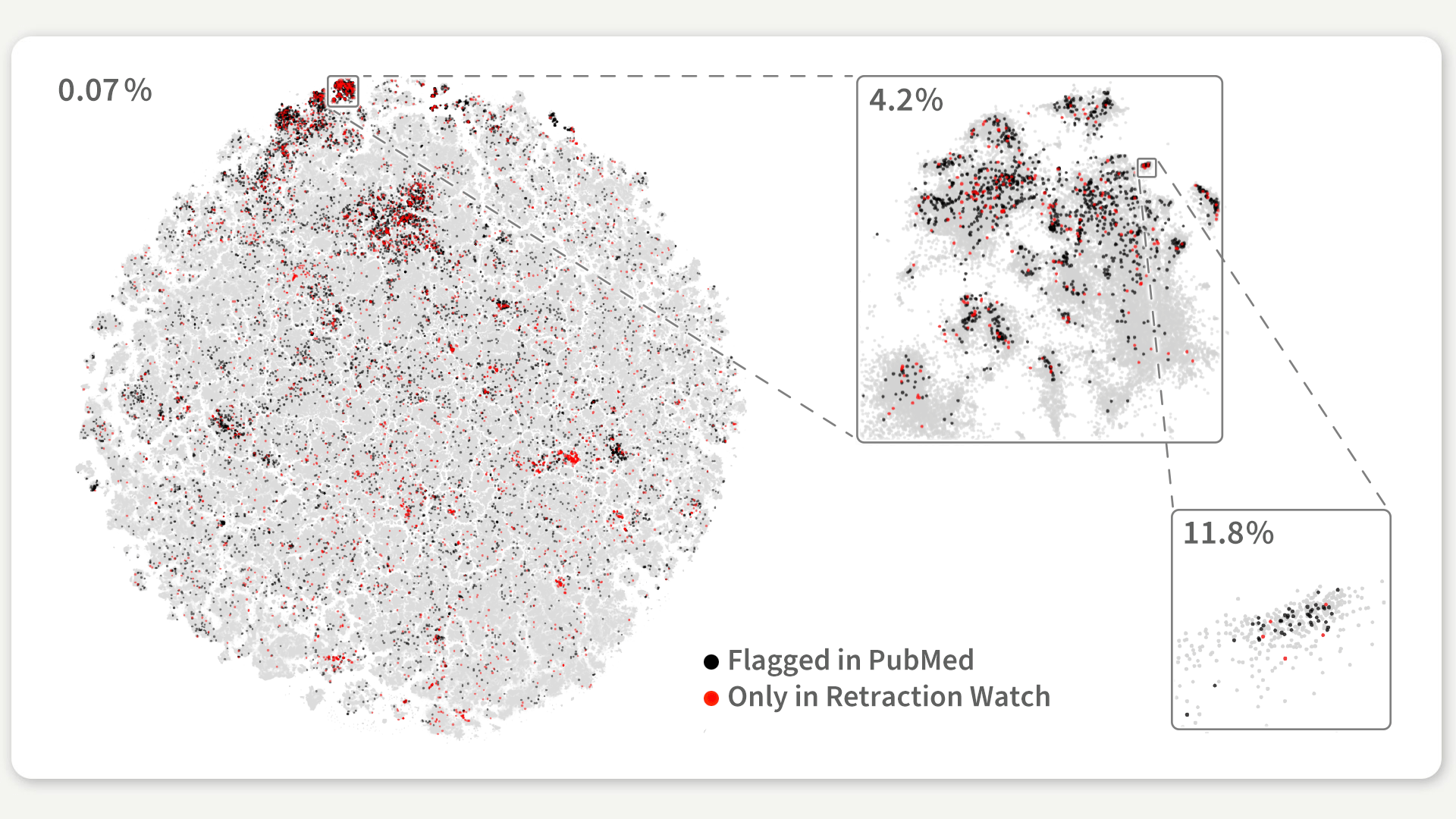
Abbildung 3: Auf der Karte sind Artikel hervorgehoben, die nach ihrer Publikation zurückgezogen wurden. Die Vergrößerung zeigt eine Region mit einem besonders hohen Anteil zurückgezogener Artikel. Die Prozentzahlen entsprechen dem Anteil der zurückgezogenen Artikel in der gesamten Karte sowie in den ausgewählten Regionen, in denen der Anteil um den Faktor 100 erhöht ist.
Diese Beispiele zeigen nur einige der vielen Möglichkeiten, wie man die wissenschaftliche Literatur mit Hilfe unserer Karte der biomedizinischen Forschungslandschaft erkunden könnte. Die Karte ermöglicht eine neue Art der interaktiven Datenerkundung, die bestehende Suchmaschinen nicht bieten können. Sie hat das Potenzial, die Art und Weise, wie Forschende die enorme Menge an biomedizinischer und biowissenschaftlicher Literatur erkunden, durchsuchen und nutzen, zu revolutionieren und damit letztlich die biomedizinische Forschung voranzutreiben.
Originalpublikation: Rita González-Márquez, Luca Schmidt, Benjamin M. Schmidt, Philipp Berens, Dmitry Kobak: The landscape of biomedical research. Patterns (2024), https://doi.org/10.1016/j.patter.2024.100968
Titelillustration: Franz-Georg Stämmele
Übersetzung ins Deutsche: Fortuna Communication

Die Monsune und den El Niño besser verstehen

Kommentare