
Children are remarkable learners, able to master new languages and learn new skills faster than adults. Yet at the same time, they might spend 30 minutes just tying their shoelaces or get distracted by a butterfly mid-sentence and run off.
Back in 1950, the famous computer scientist Alan Turing proposed a radical idea (at the time) that “[i]nstead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child’s?”. Turing was clearly not proposing to build AI that gets distracted by butterflies, but rather, AI that can learn as efficiently and effectively as human children.
But what makes children such unique learners? And how does the way we learn change as we get older?
Learning like a child and learning like an adult
Human development – the process by which children develop into adults – is truly unique in the universe, since it is the only known method that reliably produces human-level intelligence. For decades, scientists interested in both biological and artificial intelligence have been trying to understand how development shapes the way we acquire knowledge and adapt to our environment.
One of the most influential theories was proposed by the UC Berkeley scientist Alison Gopnik in 2017, who described aging as being similar to a heated piece of metal being worked by a blacksmith. Just as the metal is very hot and malleable in the beginning, children are able to flexibly adapt to new situations and acquire new skills. But over the lifespan, the metal cools down, becoming more rigid and brittle, settling into the form it has acquired.
This metaphor is already familiar to any computer scientist or machine learning researcher, since it describes a key component of most AI systems. Stochastic optimisation operates on these very same principles and played a pivotal role in the rise of deep learning methods.
All neural networks and other AI systems initially know nothing about the world and make lots of errors. In order to increase performance, parameters of the model need to be gradually adjusted. One can imagine the space of all parameter combinations as a hilly landscape, where the goal is to find the location with the lowest elevation (the lowest error). Initially, parameters are adjusted very flexibly and the algorithm is even likely to consider worse solutions as it explores the optimization landscape — like a very bouncy and chaotic tennis ball. But over time, the temperature of the algorithm cools down, and it becomes increasingly greedy and only selects solutions that lead to improvements —like a bowling ball, with a predictable downward descent. The transition from tennis ball to bowling ball corresponds to the cooling off of the optimisation algorithm.
Putting the metaphor to the test
While stochastic optimization has been used as an analogy in developmental psychology for many years, there has been a lack of concrete empirical evidence to support this theory. There is also much ambiguity in how to interpret this analogy, since the most direct interpretation is simply to understand aging as producing a gradual reduction in randomness of behaviour. But are children just more random than adults? How does that allow them to learn so efficiently?
This ambiguity prompted us to finally put the analogy between human development and stochastic optimisation to an empirical test. To do so, we had 281 people between the ages of 5 and 55 play a very intuitive game where they searched for rewards on a grid and acquired points.
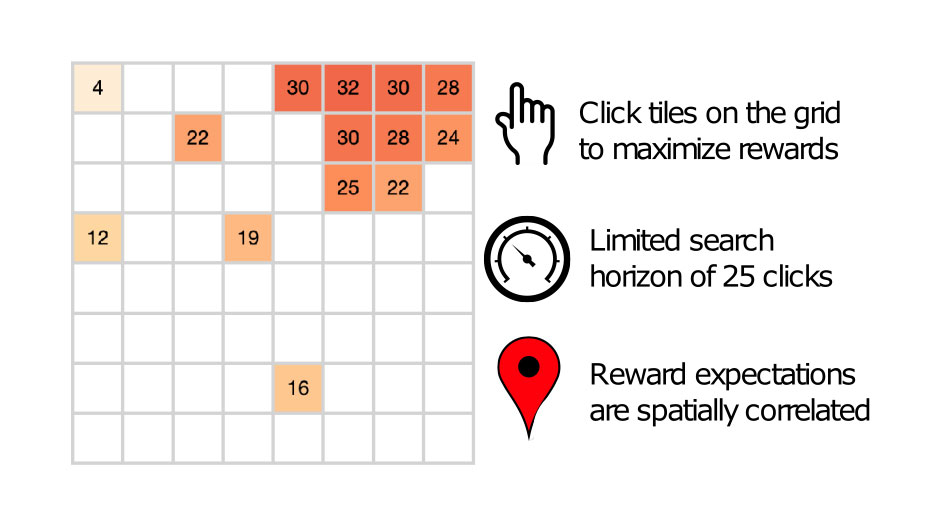
Figure 1. Experiment. Participants clicked tiles on the grid to acquire points. Initially only a single random tile is revealed, and participants have a total of 25 clicks. Because nearby tiles tend to have similar rewards, participants can use the spatial reward structure to search more efficiently. Imagine you are on vacation in a new city, and you don’t know which parts of the city are nice to visit. But as you get to know the city, you can start to predict that nice places are likely to be in similar areas to where you had a positive experience.
Three dimensions of learning
We then analysed behavioural patterns and fit computational models to participant choices. The models resemble the kind used to train self-driving cars or play games such as Go. But here, they are designed to provide psychologically meaningful insights into different aspects of learning. In particular, we focused on three dimensions of learning: how we adapt to new situations based on our previous experiences (generalisation), how curious we are about new situations (exploration), and the randomness of our decisions.
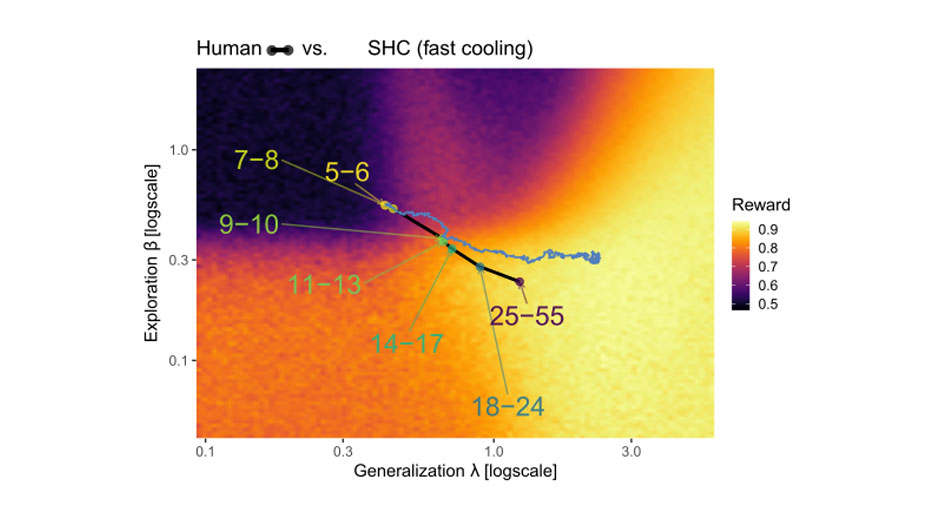
Figure 2. Developmental trajectory of humans (coloured dots) compared against the best performing optimisation algorithm (squiggly blue line).
Children are not just random
Contrary to the most common interpretation, growing up does not only correspond to a reduction in randomness. Instead, development appears to resemble an optimisation process that takes place along all dimensions of learning that we considered. We observed rapid changes during childhood, corresponding to exploration and experimentation with different learning strategies. As we get older, however, these parameters begin to stabilise and converge towards more efficient combinations.
For the first time, we were able to directly compare the developmental trajectory of humans (how the three dimensions of learning change over the lifespan) to various optimization algorithms, as they tweak the parameters of learning over multiple iterations on the same task that human participants played. The results are in Figure 2, where the best performing algorithm, the one that gained the highest reward, most closely resembled the process of human development.
Remarkable efficiency of human learning
While there were important differences between how humans and algorithms converged, none of the optimisation algorithms ended up reliably better than adult humans. This suggests a remarkable efficiency of human development.
The differences between humans and the algorithm trajectories are also very exciting, since they inform us about the cost-efficiency of human learners. Like a long-distance runner or an energy efficient kitchen appliance, we don’t only optimise for maximum performance, but are also sensitive to costs. Some learning strategies incur greater computational costs, and divergences between the human and algorithm data shed light on the nature of these costs.
Insights into developmental disorders and psychiatry
This work also has important implications for how the environment that children grow up in can contribute towards developmental and psychiatric disorders. When there is a mismatch between the environment children are optimizing and the grown-up world they later inhabit, maladaptive behaviours can arise. For instance, children who grow up in poverty or a refugee camp will be optimising for environments of scarcity and instability, which can lead to maladaptive traits in adulthood. For instance, through an inability to work towards long-term goals or inability to focus.
Conclusion
Our work shows how beyond only providing a source for analogies, machine learning can be used to directly test theories of human development, with insights into possible causes for developmental and psychiatric disorders.
Original publication:
Cover illustration: Franz-Georg Stämmele
Comments